如何实现一个高效的 hashTable
散列法存储的基本思想是:由节点的关键码值决定节点的存储地址。散列技术除了可以用于查找外,还可以用于存储 散列和数组的关系
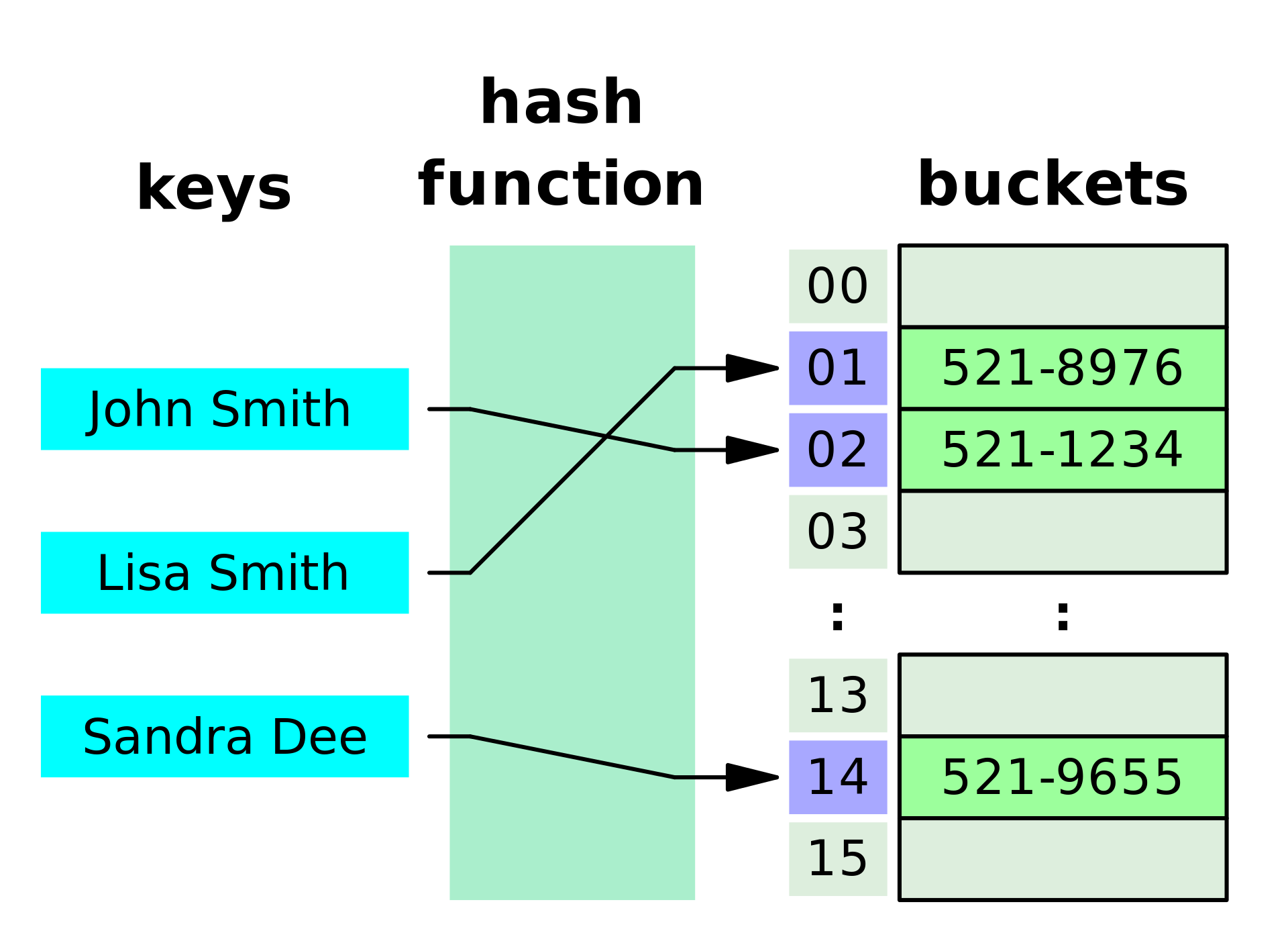
散列法存储的基本思想是:由节点的关键码值决定节点的存储地址。散列技术除了可以用于查找外,还可以用于存储
存储
散列表用的是数组支持按照下标随机访问数据的特性,所以散列表其实就是数组的一种扩展,由数组演化而来。可以说,如果没有数组,就没有散列表
散列表用的就是数组支持按照下标随机访问的时候,时间复杂度是 O(1) 的特性。我们通过散列函数把元素的键值映射为下标,然后将数据存储在数组中对应下标的位置。当我们按照键值查询元素时,我们用同样的散列函数,将键值转化数组下标,从对应的数组下标的位置取数据
hash 算法
- 散列函数的设计不能太复杂
- 散列函数生成的值要尽可能随机并且均匀分布
散列冲突
关于散列冲突解决方法的选择,我对比了开放寻址法和链表法两种方法的优劣和适应的场景。
- 大部分情况下,链表法更加普适。而且,我们还可以通过将链表法中的链表改造成其他动态查找数据结构,比如红黑树,来避免散列表时间复杂度退化成 O(n),抵御散列碰撞攻击。
- 但是,对于小规模数据、装载因子不高的散列表,比较适合用开放寻址法。
开放选址
线性探测(Linear Probing)
二次探测(Quadratic probing)
双重散列(Double hashing
- 如果相等,则说明就是我们要找的元素;否则就顺序往后依次查找。
- 如果遍历到数组中的空闲位置,还没有找到,就说明要查找的元素并没有在散列表中
装载因子
- 过大了怎么办
针对数组的扩容,数据搬移操作比较简单。但是,针对散列表的扩容,数据搬移操作要复杂很多,因为散列表的大小变了,数据的存储位置也变了,所以我们需要通过散列函数重新计算每个数据的存储位置。